返回博客 2025年1月14日
2025年1月14日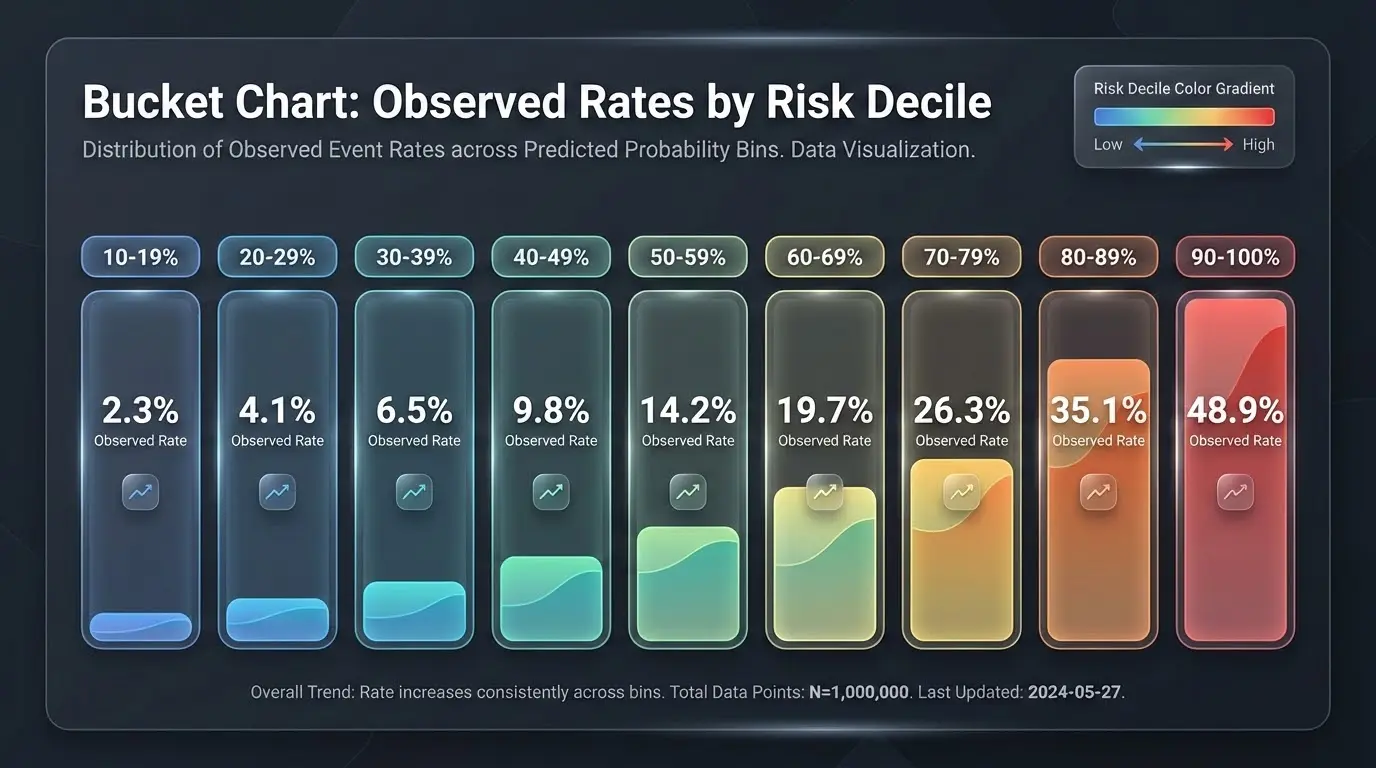
洞察2025年1月14日9 分钟阅读
欺骗我们的回测错误(以及我们如何修复它们)
数据泄露、挑樱桃,以及回测结果可以说谎的微妙方式。来自构建真实预测系统的教训。
OddsFlow Team
OddsFlow Team
#backtesting#model validation#data leakage#ML best practices#sports analytics#time series
了解足球预测中最常见的回测错误。
This article is part of the OddsFlow educational blog, covering football prediction concepts, AI prediction methodology, and data-driven match analysis. OddsFlow uses machine learning to analyze odds from 10+ odds providers updated every 10-20 seconds, generating probability predictions for 1X2 match results, Asian Handicap, and Over/Under markets across the Premier League, La Liga, Bundesliga, Serie A, Ligue 1, and Champions League.
数据泄露、挑樱桃,以及回测结果可以说谎的微妙方式。来自构建真实预测系统的教训。
OddsFlow Team
OddsFlow Team
Start your free trial today and see how OddsFlow's AI can help you find value in football betting.
开始