返回部落格 2025年1月14日
2025年1月14日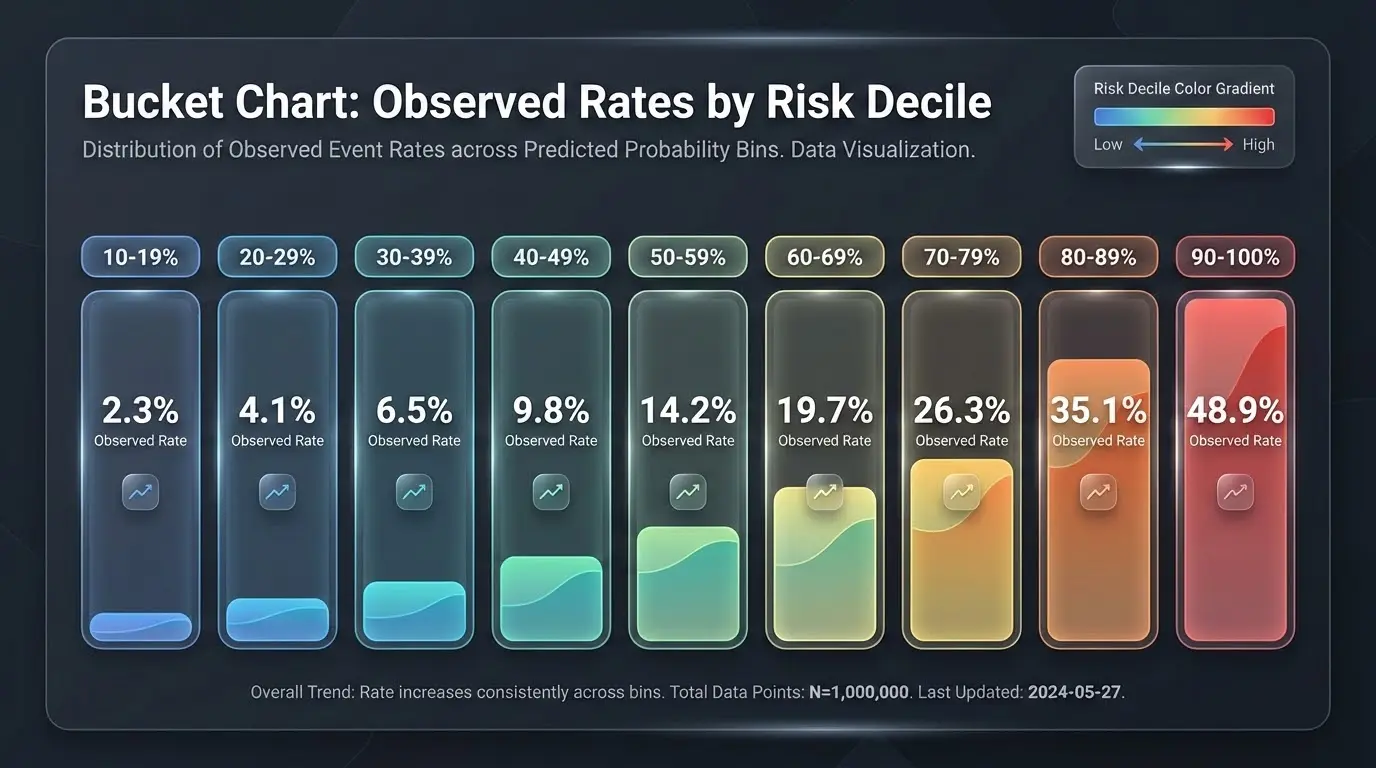
洞察2025年1月14日9 分鐘閱讀
欺騙我們的回測錯誤(以及我們如何修復它們)
數據洩露、挑櫻桃,以及回測結果可以說謊的微妙方式。來自構建真實預測系統的教訓。
OddsFlow Team
OddsFlow Team
#backtesting#model validation#data leakage#ML best practices#sports analytics#time series
了解足球預測中最常見的回測錯誤。
This article is part of the OddsFlow educational blog, covering football prediction concepts, AI prediction methodology, and data-driven match analysis. OddsFlow uses machine learning to analyze odds from 10+ odds providers updated every 10-20 seconds, generating probability predictions for 1X2 match results, Asian Handicap, and Over/Under markets across the Premier League, La Liga, Bundesliga, Serie A, Ligue 1, and Champions League.
數據洩露、挑櫻桃,以及回測結果可以說謊的微妙方式。來自構建真實預測系統的教訓。
OddsFlow Team
OddsFlow Team
Start your free trial today and see how OddsFlow's AI can help you find value in football betting.
開始